Saptak's Blog Posts
Making my first OnionShare release
Posted: 2024-02-29T18:11:14+05:30One of the biggest bottlenecks in maintaining the OnionShare desktop application has been packaging and releasing the tool. Since OnionShare is a cross platform tool, we need to ensure that release works in most different desktop Operating Systems. To know more about the pain that goes through in making an OnionShare release, read the blogs[1][2][3] that Micah Lee wrote on this topic.
However, one other big bottleneck in our release process apart from all the technical difficulties is that Micah has always been the one making the releases, and even though the other maintainers are aware of process, we have never actually made a release. Hence, to mitigate that, we decided that I will be making the OnionShare 2.6.1 release.
PS: Since Micah has written pretty detailed blogs with code snippets, I am not going to include much code snippets (unless I made significant changes) to not lengthen this already long code further. I am going to keep this blog more like a narrative of my experience.
Getting the hardwares ready
Firstly, given the threat model of OnionShare, we decided that it is always good to have a clean machine to do the OnionShare release works, especially the signing part of things. Micah has already automated a lot of the release process using GitHub Actions over the years, but we still need to build the Apple Silicon versions of OnionShare manually and then merge with the Intel version to create a univeral2 app bundle.
Also, in general, it's a good practise to have and use the signing keys in a clean machine for a projective as sensitive as OnionShare that is used by people with high threat models. So I decided to get a new Macbook for the same. This would help me build the Apple Silicon version as well as sign the packages for the other Operating Systems.
Also, I received the HARICA signing keys from Glenn Sorrentino that is needed for signing the Windows releases.
Fixing the bugs, merging the PRs
After the 2.6.1-dev release was created, we noticed some bugs that we wanted to fix before making the 2.6.1. We fixed, reviewed and merged most of those bugs. Also, there were few older PRs and documentation changes from contributors that I wanted to be merged before making the release.
Translations
Localization is an important part of OnionShare since it enables users to use OnionShare in the language they are most comfortable with. There were quite some translation PRs. Also, emmapeel2 who always helps us with weblate wizardry, made certain changes in the setup, which I also wanted to include in this release.
After creating the release PR, I also need to check which languages are greater than 90% translated, and make a push to hopefully making some more languages pass that threshold, and finally make the OnionShare release with only the languages that cross that threshold.
Making the Release PR
And, then I started making the release PR. I was almost sure that since Micah had just made a dev release, most things would go smoothly. But my big mistake was not learning from the pain in Micah's blog.
Updating dependencies in Snapcraft
Updating the poetry dependencies went pretty smoothly.
There was nothing much to update in the pluggable transport scripts as well.
But then I started updating and packaging for Snapcraft and Flatpak. Updating tor versions to the latest went pretty smoothly. In snapcraft, the python dependencies needed to be compared manually with the pyproject.toml. I definitely feel like we should automate this process in future, but for now, it wasn't too bad.
But trying to build snap with snapcraft locally just was not working for me in my system. I kept getting lxd errors that I was not fully sure what to do about. I decided to move ahead with flatpak packaging and wait to discuss the snapcraft issue with Micah later. I was satisfied that at least it was building through GitHub Actions.
Updating dependencies in Flatpak
Even though I read about the hardship that Micah had to go through with updating pluggable transports and python dependencies in flatpak packaging, I didn't learn my lesson. I decided, let's give it a try. I tried updating the pluggable transports and faced the same issue that Micah did. I tried modifying the tool, even manually updating the commits, but something or the other failed.
Then, I moved on to updating the python dependencies for flatpak. The generator code that Micah wrote for desktops worked perfectly, but the cli gave me pain. The format in which the dependencies were getting generated and the existing formats were not matching. And I didn't want to be too brave and change the format, since flatpak isn't my area of expertise. But, python kind of is. So I decided to check if I can update the flatpak-poetry-generator.py files to work. And I managed to fix that!
That helped me update the dependencies in flatpak.
MacOS and Windows Signing fun!
Creating Apple Silicon app bundle
As mentioned before, we still need to create an Apple Silicon bundle and then merge it with the Intel build generated from CI to get the universal2 app bundle. Before doing that, need to install the poetry dependencies, tor dependencies and the pluggable transport dependencies.
And I hit an issue again: our get-tor.py script is not working.
The script failed to verify the Tor Browser version that we were downloading. This has happened before, and I kind of doubted that Tor PGP script must have expired. I tried verifying manually and seems like that was the case. The subkey used for signing had expired. So I downloaded the new Tor Browser Developers signing keys, created a PR, and seems like I could download tor now.
Once that was done, I just needed to run:
/Library/Frameworks/Python.framework/Versions/3.11/bin/poetry run python ./setup-freeze.py bdist_mac
rm -rf build/OnionShare.app/Contents/Resources/lib
mv build/exe.macosx-10.9-universal2-3.11/lib build/OnionShare.app/Contents/Resources/
/Library/Frameworks/Python.framework/Versions/3.11/bin/poetry run python ./scripts/build-macos.py cleanup-build
And amazingly, it built successfully in the very first try! That was easy! Now I just need to merge the Intel app bundle and the Silicon app bundle and everything should work (Spoiler alert: It doesn't!).
Once the app bundle was created, it was time to sign and notarize. However, the process was a little difficult for me to do since Micah had previously used an individual account. So I passed on the universal2 bundle to him and moved on to signing work in Windows.
Signing the Windows package
I had to boot into my Windows 11 VM to finish the signing and making the windows release. Since this was the first time I was doing the release, I had to first get my VM ready by installing all the dependencies needed for signing and packaging. I am not super familiar with Windows development environment so had to figure out adding PATH and other such things to make all the dependencies work. The next thing to do was setting up the HARICA smart card.
Setting up the HARICA smart card
Thankfully, Micah had already done this before so he was able to help me out a bit. I had to log into the control panel, download and import certificates to my smart card and change the token password and administrator password for my smart card. Apart from the UI of the SafeNet client not being the best, everything else went mostly smoothly.
Since Micah had already made some changes to fix the code signing and packaging stuff, it went pretty smooth for me and I didn't face much obstructions. Science & Design, founded by Glenn Sorrentino (who designed the beautiful OnionShare UX!), has taken on the role of fiscal sponsor for OnionShare and hence the package now gets signed under the name of Science and Design Inc.
Meanwhile, Micah had got back to me saying that the universal2 bundle didn't work.
So, the Apple Silicon bundle didn't work
One of the mistakes that I made was I didn't test my Apple Silicon build. I thought I will test it once it is signed and notarized. However, Micah confirmed that even after signing and notarizing, the universal2 build is not working. It kept giving segmentation fault. Time to get back to debugging.
Downgrading cx-freeze to 6.15.9
The first thought that came to my mind was, Micah had made a dev build in October 2023. So the cx-freeze release from that time should still be building correctly. So I decided to try and do build (instead of bdist_mac) with the cx-freeze version at that time (which was 6.15.9) and check if the binary created works. And thankfully, that did work. I tried with 6.15.10 and it didn't. So I decided to stick to 6.15.9.
So let's try now running bdist_mac, create a .app bundle and hopefully everything will work perfectly! But nope! The command failed with:
OnionShare.app/Contents/MacOS/frozen_application_license.txt: No such file or directory
So now I had a decision to make, should I try to monkey-patch this and just figure out how to fix this or try to make the latest cx-freeze work. I decided to give the latest cx-freeze (version 6.15.15) another try.
Trying zip_include_packages
So, one thing I noticed we were doing differently than what cx-freeze documentation and examples for PySide6 mentioned was we put our dependencies in packages, instead of zip_include_packages in the setup options.
"build_exe": {
"packages": [
"cffi",
"engineio",
"engineio.async_drivers.gevent",
"engineio.async_drivers.gevent_uwsgi",
"gevent",
"jinja2.ext",
"onionshare",
"onionshare_cli",
"PySide6",
"PySide6.QtCore",
"PySide6.QtGui",
"PySide6.QtWidgets",
],
"excludes": [
"test",
"tkinter",
...
],
...
}
So I thought, let's try moving all of the depencies into zip_include_packages from packages. Basically zip_include_packages includes the dependencies in the zip file, whereas packages place them in the file system and not the zip file. My guess was, the Apple Silicon configuration of how a .app bundle should be structured has changed. So the new options looked something like this:
"build_exe": {
"zip_include_packages": [
"cffi",
"engineio",
"engineio.async_drivers.gevent",
"engineio.async_drivers.gevent_uwsgi",
"gevent",
"jinja2.ext",
"onionshare",
"onionshare_cli",
"PySide6",
"PySide6.QtCore",
"PySide6.QtGui",
"PySide6.QtWidgets",
],
"excludes": [
"test",
"tkinter",
...
],
...
}
So I created a build using that, ran the binary, and it gave an error. But I was happy, because it wasn't segmentation fault. The error mainly because it was not able to import some functions from onionshare_cli. So as a next step, I decided to move everything apart from onionshare and onionshare_cli to zip_include_packages. It looked something like this:
"build_exe": {
"packages": [
"onionshare",
"onionshare_cli",
],
"zip_include_packages": [
"cffi",
"engineio",
"engineio.async_drivers.gevent",
"engineio.async_drivers.gevent_uwsgi",
"gevent",
"jinja2.ext",
"PySide6",
"PySide6.QtCore",
"PySide6.QtGui",
"PySide6.QtWidgets",
],
"excludes": [
"test",
"tkinter",
...
],
...
}
This almost worked. Problem was, PySide 6.4 had changed how they deal with ENUMs and we were still using deprecated code. Now, fixing the deprecations would take a lot of time, so I decided to create an issue for the same and decided to deal with it after the release.
At this point, I was pretty frustrated, so I decided to do, what I didn't want to do. Just have both packages and zip_include_packages. So I did that, build the binary and it worked. I decided to make the .app bundle. It worked perfectly as well! Great!
I was a little worried that adding the dependencies in both packages and zip_include_packages might increase the size of the bundle, but surprisingle, it actually decreased the size compared to the dev build. So that's nice! I also realized that I don't need to replace the lib directory inside the .app bundle anymore. I ran the cleanup code, hit some FileNotFoundError, tried to find if the files were now in a different location, couldn't find them, decided to put them in a try-except block.
After that, I merged the silicon bundle with Intel bundle to create the universal2 bundle again, sent to Micah for signing, and seems like everything worked!
Creating PGP signature for all the builds
Now that we had all the build files ready, I tried installing and running them all, and seems like everything is working fine. Next, I needed to generate PGP signature for each of the build files and then create a GitHub release. However, Micah is the one who has always created signatures. So the options for us now were:
- create an OnionShare GPG key that everyone uses
- sign with my GPG and update documentations to reflect the same
The issue with creating a new OnionShare GPG key was distribution. The maintainers of OnionShare are spread across timezones and continents. So we decided to create signature with my GPG and update the documentation on how to verify the downloads.
Concluding the release
Once the signatures were done, the next steps were mostly straightforward:
- Create a GitHub release
- Publish onionshare-cli on PyPi
- Push the build and signatures to the onionshare.org servers and update the website and docs
- Create PRs in Flathub and Homebrew cask
- Make the snapcraft edge to stable
The above went pretty smooth without much difficulty. Once everything was merged, it was time to make an announcement. Since Micah has been doing the announcements, we decided to stick with that for the release so that it reaches to more people.
Google Open Source Peer Bonus Award 2023
Posted: 2023-04-20T13:02:22+05:30I am honored to be a recipient of the Google Open Source Peer Bonus 2023. Thank you Rick Viscomi for nominating me for my work with the Web Almanac 2022 project. I was the author of Security and Accessibility chapters of the Web Almanac 2022.

For the last year, I have started to spend more time in contributing, maintaining and creating Open Source project and reduced the amount of contracts I usually would do. So this letter of appreciated feels great and helps me get an additional boost in continuing to do Open Source Projects.
Some of the other Open Source projects that I have been contributing and trying to spend more time on are:
In case someone is interested in supporting me to continue doing open source projects focused towards security, privacy and accessibility, I also created a GitHub Sponsors account.
What to expect from GSoC?
Posted: 2019-03-10T16:06:00+05:301. Don't "Crack" GSoC
Unlike many other computer science and engineering programs, there is no pill that you take and you magically get selected overnight. Nor is there a particular curriculum or book that you can read over and over and practice and get selected.Getting selected in GSoC is a gradual process that needs lots of patience and contribution and the slow but steady accrual of experience. So if you are actually reading this blog in an attempt to know how to get selected, you are kind of late in the process. Better late than never, though.
The only way you get selected in GSoC (at least in most organisations) is via Open Source Contributions. So now you might think, okay, open source contribution is the curriculum.
Yes and no.
If you consider open source as yet another chapter in your coursework, then getting started with open source contribution might be difficult.
There's a lot involved; from clean, readable coding to best practices to communication. It is an entirely new way of working (way of life?) that is going to last you forever and help you in the long run.
For many, like us (like me personally), it's more than even that. It's a belief, a principle, a movement. I am going to talk more about that in the points below.
So even though many blogs will tell you exactly how to pick an issue, and show many contributions and help you pick an easy organisation, I’d encourage you to enjoy the process and get involved wholeheartedly in it. Contribute to the project and organisation you feel excited about. Become a part of the organisation, get to know folks, learn as much as you can, expand your pool of knowledge. If after all that, the worst happens and you are not selected for GSoC, you can still keep contributing to a major open source project which is awesome!
2. Do it for Open Source, Not for Money
I know money is a really important part of life (and I am not denying that) and GSoC money is definitely tempting. So I am not complaining about the money being an intrinsic motivation. What I am trying to say is if you do GSoC only for the money, and stop contributing to Open Source after these 3 months, then the purpose of GSoC is lost.GSoC, I believe, is meant to be a platform that helps you get started in your Open Source journey. It is that small little push that you need to start contributing to open source projects. Finding and contributing to an organisation all on your own might be a little difficult, GSoC provides you with a platform that helps you find them more easily and have a higher chance of starting your open source contribution in major organisation than you would normally do.
So use GSoC as a vehicle to begin your journey in the open source world. Once you start seeing it from that perspective, you will, hopefully appreciate the principles of open source and keep contributing to the open source world.
Open source projects appreciate great developers like you, so come be a part of it.
3. Take PR Reviews Positively
Now, if you have already grasped the previous points, you know GSoC is only the beginning. Apart from making all projects by you open source, a really important part of the journey is contributing to various wonderful open source projects, which is actually going to be most of your GSoC. And with contribution, comes pull requests (or patches in some cases).Most times, you will receive plenty of comments and reviews on your pull requests. I have seen many folks get irritated. Many in face, feel that if you can't get a pull request merged without too many reviews, then that organisation is hard to contribute to, in GSoC. This causes many to try for organisations where pull requests get easily merged.
Don't be discouraged by the reviews.
Instead, use them as a learning opportunity. Most reviews are very constructive criticism that are will serve you well throughout your life. It will help you write code that is more readable, more efficient and code that works best in production both in terms of performance and maintainability. In GSoC you get to learn all this directly from upstream projects with super awesome developers and coders … and PR review is where you learn the most.
4. Collaborate, Don't Compete
Over the years, as both student and mentor in GSoC, I’ve seen participants duking it out for issues or work in organisations and projects. This is mainly because everyone has this feeling that if they solve more issues and bugs, they have a higher chance of getting selected or passing the evaluation. But at the same time, this often causes frustration if a PR is getting too many comments. Also, participants tend to start working on something different, leaving their previous work incomplete.All these will actually just create a bad impression to the mentors and others in the organisation. It will deprive you of lots of peer learning opportunities because you will always be competing with everyone. So, try your best to collaborate with other participants and even the mentors and other contributors.
Collaboration is a central principle in the Open Source community at large. Collaborating with each other not only helps you learn a lot from your peers but also leads to a better, much cleaner project. Collaborate not only on code, but on shaping the best practices of a project, on blogs, on writing documentation and setting guidelines. You will also have a better overview of the entire project rather than just the small piece you work on.
Remember, GSoC is not a competition where you need to be the top scorer to win. Everyone is a winner if they contribute to the projects and help in growing the project. Believe me, most organisations will pass you even when you don't complete the entire proposal you made, if you made other quality contributions to the project and they feel that your work has helped in furthering development of the overall project.
5. Be Part of the Community
While being a part of GSoC, don't just code. Go, be a part of various open source communities. When you are selected for a particular organisation, be always active in their communication channels, be it IRC or slack or gitter or what have you. Help newcomers get started with the project, attend team meetings, make friends, and communicate with everyone. If possible, try to attend different meetups and conferences near your area.These will help you network and make friends with a lot of people from different parts of the open source communities and you will get to learn even more. The best part about open source is that it allows you to grow beyond any boundaries and being part of different communities is one of the best ways to do this. Not only will you get to learn a lot code wise, but also about different aspects of life and technology and incidents that might help you shape your future.
And, most importantly, continue being involved in these communities even after GSoC ends. I have told plenty of folks, plenty of times before and I can't emphasise enough that GSoC is just the beginning of your journey. Your journey with open source coding and the communities, doesn't end after the 3 months of GSoC. It starts expanding. Yes, due to various circumstances, you might not always be able to actively contribute code to an open source project, but try to carve out time to help others in communities get started. Try to apply the lessons you learn in the communities, in your office work or university projects and when you do get time, contribute to the open source!
In The Heat of Code : A Mentor's POV
Posted: 2017-03-28T21:23:00+05:30
In The Heat of Code or CodeHeat, as it is famously known right now started when Mario Behling started a discussion with me about how to encourage continuous contribution to projects by FOSSASIA even after GSoC. The scenario was most of the time students or participants stopped contributing after Google Summer of Code ended because there wasn't much incentive or profit of their's in continuing with the projects. So we decided to give people a reason to continue. In fact why just continue? Why not get completely new contributors??? And without distinguishing whether they were in university or school or working professionals. So we got others in FOSSASIA team also to drafting the idea into a proper event. And thus began CodeHeat. The official announcement was made in September 20th. The coding started on September 25th. I was to be a mentor in the Open Event Organizer Server project. And the registrations started coming.
We had a huge number of registrations but sadly there were very few contributions in the Open Event Organizer Server project. Most of the participants were more interested and enthusiastic in contributing to android app development and our project got a little less attention. Nonetheless, I and Niranjan continued our own contributions and reviewed occassional pull requests we received. It was almost end of November and though CodeHeat was going great I wasn't very happy as a mentor since our project didn't get much contributors.
Then in the beginning of December few of my friends from college asked me about codeheat and said they were interested in Python. I was delighted and introduced them to Open Event Organizer Server project. Soon there were participants from other colleges as well. We started getting more and more contributions. Then there were 2 participants - Shubham Padia and Medozonuo who were not only contributing but were almost competing with each other. The result of their competition was we got huge number of awesome code contributions from both of them in all areas from frontend to backend to even database improvements.
From implementing the entire discount and access code system to providing more options and making it more customizable for CFS to solving tons of frontend bugs and export functionality, I and Niranjan almost started having a hard time reviewing their PRs since there were tons of them. I was delighted. The project was nearing release more and more and it was reaching a stage where we can actually make an attempt to use it in production. I and Niranjan often discussed how we hoped these 2 make to the top ten in CodeHeat. It was almost like reliving GSoC from a mentor's perspective.

Finally it was result time. Though it would be wrong to say I was nervous but I surely was excited to know whether any of the contributors of open event organizer server project made it to the top ten. To my utter happiness not only did they make to top ten but Shubham Padia and Medozonuo made it to the top 3. I was really happy for them since they truly deserved it. I guess Niranjan would agree with me in saying that we truly loved mentoring them. It wasn't like they knew each and everything but they picked up stuff pretty quickly and showed their contribution in all aspects of the code. Also, we were later able to get their help in reviewing other's code which was really helpful for me and Niranjan.
It was a really wonderful experience, mentoring in CodeHeat, reviewing PRs day and night, sharing knowledge with others. I simply loved the experience. The icing on the cake was 2 of the top 3 were contributors to open event organizer project. A lot many mentoring experiences are on the queue and I am really looking forward to them.
PyCon India 2016 : A weekend to remember
Posted: 2016-10-05T01:29:00+05:30
PyCon India is one of the best experiences I have had in recent past. PyCon India this year was held in New Delhi from 23rd September to 25th September, 2016. Three days filled with learning, interaction, meeting like minded people; couldn't have asked for anything more. The entire was one of python and development and I loved it.
Day 1 - Devsprint

Day 2 - Volunteering Experience
Day 3 - Last Day

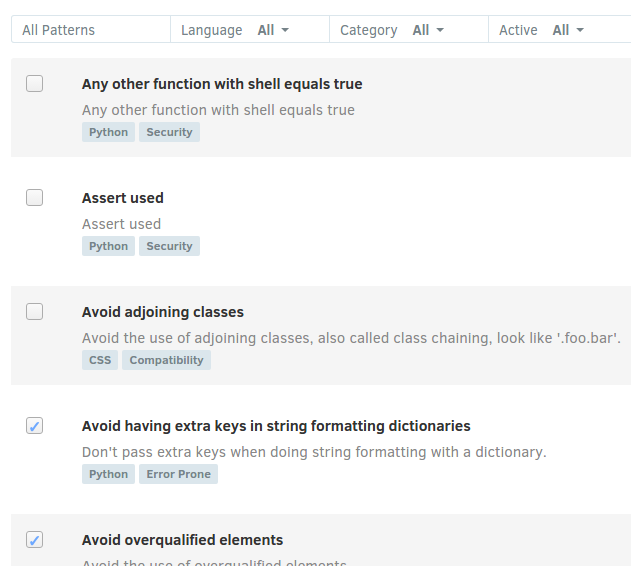
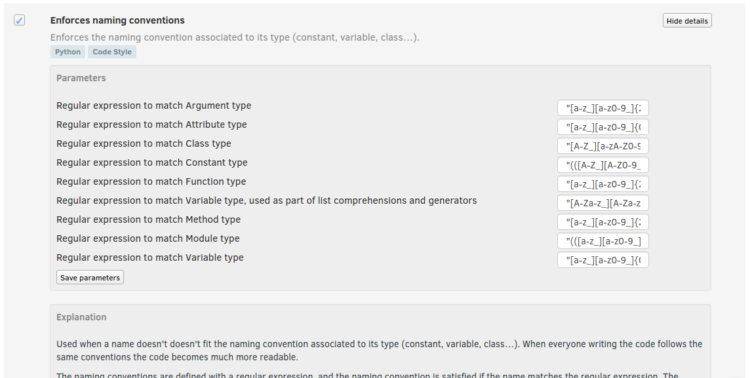
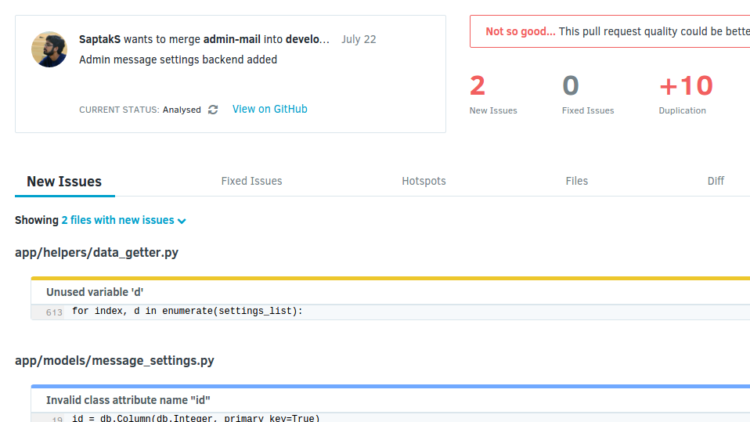
Configuring Codacy : Use Your Own Conventions
Posted: 2016-07-23T02:12:00+05:30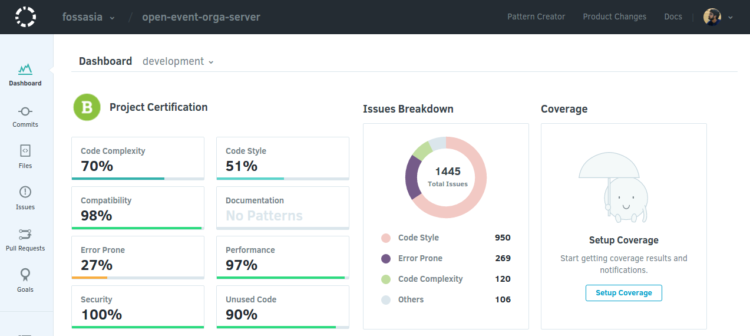
- Code Pattern - List of all the checks available on codacy to review your code
- Settings - Settings involving github repository url, codacy badge, repository name, etc.